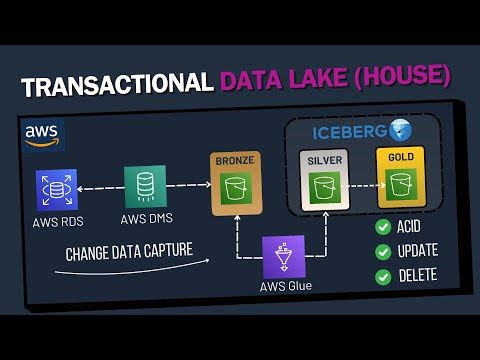
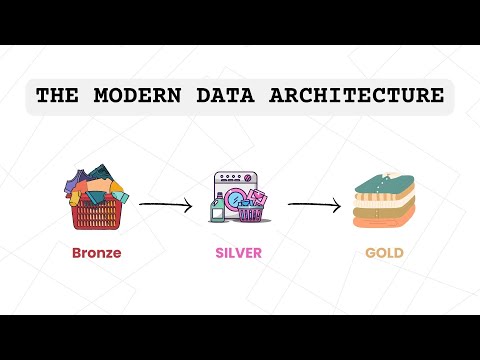
🚀 In this hands-on tutorial, you’ll learn how to build a medallion architecture in Databricks using LakeFlow Declarative Pipelines. We walk through cleaning raw data, applying built-in data quality checks, and creating gold-level aggregations and joins—all fully orchestrated with LakeFlow Jobs. This is part 4 of our end-to-end Databricks project for a smart insurance use case. 🔗 Connect With Me on LinkedIn: ⌛ Timestamps 0:00 – Intro 2:27 – Data Quality & Cleaning - Silver Layer 15:35 – Data Aggregation - Gold Layer 21:10 – Orchestration 25:51 – Outro
- 4740Просмотров
- 3 месяца назадОпубликованоThomas Hass
Build a Medallion Architecture with Databricks Lakeflow | Data Quality, Aggregation & Orchestration
Похожее видео









Популярное
Новини