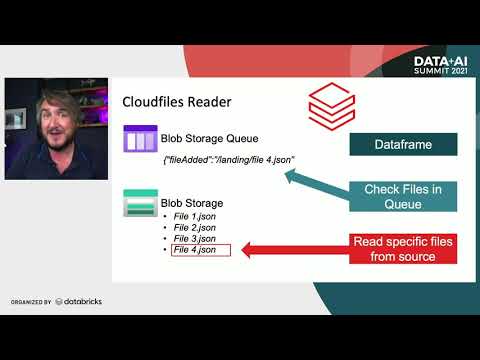
🚀 In this hands-on tutorial, I show you how to incrementally ingest files from object storage (like S3 or ADLS) into Databricks using Auto Loader and LakeFlow Declarative Pipelines. You’ll learn how to handle schema evolution, track processed files, and automatically archive ingested data using the new Clean Source feature—all without writing complex ingestion logic. 🔗 Connect With Me on LinkedIn: ⌛ Timestamps 0:00 – Intro 1:33 – Autoloader Example 6:46 – Schema Evolution 12:41 – Archiving with cleanSource 16:32 – Outro
- 2936Просмотров
- 4 месяца назадОпубликованоThomas Hass
Master Databricks Auto Loader Incremental File Ingestion | S3, ADLS, GCS | E2E #3
Похожее видео







Популярное
Новини