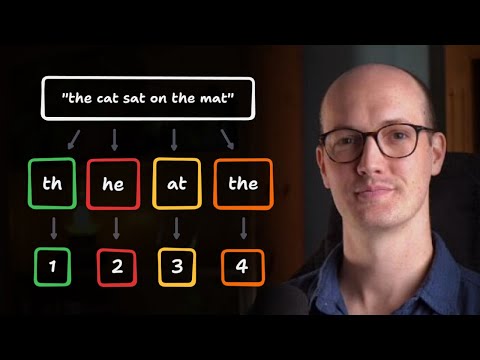
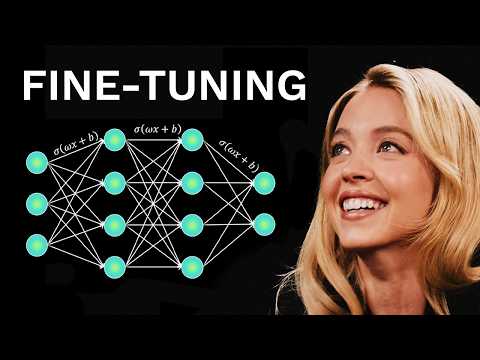
Tired of LLMs giving you generic responses that miss the mark? In this video, we'll explain how to train and fine-tune large language models on your data. Whether you're a developer, data scientist, or tech team lead, this tutorial breaks down the entire process into actionable steps. 🚀 Get the data you need with our Web Scraping API: What you'll learn: ✅ The difference between training from scratch vs. fine-tuning (and when to use each) ✅ How to prepare high-quality training data ✅ Step-by-step process for training/fine-tuning LLMs on custom datasets ✅ Essential tools and infrastructure setup ✅ Best practices for evaluation, deployment, and monitoring Timestamps: 00:00 Training vs Fine-Tuning: What’s the Difference? 01:04 Requirements for LLM Training 01:27 What Determines Training Data Quality 02:08 8 Steps of LLM Training/Fine-Tuning FAQ: ❓ How much data do I need for fine-tuning? There's no magic number: it depends on your task complexity and model size. You can achieve good results with surprisingly little data, if it's high-quality and consistent. ❓ What's the difference between training and fine-tuning? Training builds an LLM's knowledge from scratch using massive datasets and resources. Fine-tuning starts with a pre-trained model and adapts it using your specific data. ❓ How do I know if my model is overfitting? Monitor your validation metrics during training. If training accuracy looks great but validation performance drops, that's overfitting. Use a separate validation dataset to catch this early. ❓ What tools do I need to get started? Essential tools include Python, PyTorch, TensorFlow, and Hugging Face Transformers. Keep everything modular and version-controlled. Let's connect on other platforms! 🔹 : 🔹 Discord community: 🔹 GitHub: Need some direct support? 🔹 For sales queries, email: sales@ 🔹 24/7 live customer support:
- 8623Просмотров
- 3 месяца назадОпубликованоDecodo (formerly Smartproxy)
How to Train an LLM on Your Own Data: Tips for Beginners
Похожее видео









Популярное
Новини