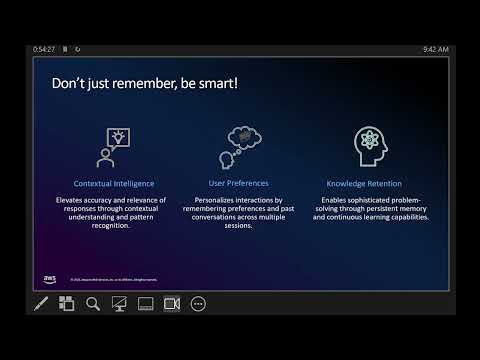
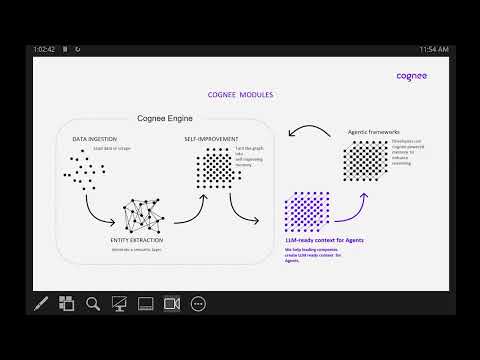
Tina Tsou, TSC Chair, InfiniEdge AI (LF Edge) , describes how agent stacks are getting heavier, multiple models, long contexts, streaming tools, and memory becomes the bottleneck long before compute does. This talk shows how to design “memory-aware” agent workflows that run reliably on geo-distributed GPU clusters. We’ll cover practical patterns for KV-cache reuse and eviction, offloading and prefetching strategies, smart checkpointing to survive failures, and sharding vector/RAG state across sites without killing latency. I’ll share real numbers from InfiniEdge AI code labs: how we cut p95 latency and memory footprint while keeping answer quality stable, and which trade-offs matter most (token-window vs. cache size, node locality vs. recall). You’ll leave with a reference blueprint and a checklist you can apply this month to make your agents cheaper, faster, and more robust.
- 14Просмотров
- 2 недели назадОпубликованоAI Memory Forum
Memory Aware Agents at the Edge Fast, Reliable RAG on Geo Distributed GPUs
Похожее видео








Популярное
Новини