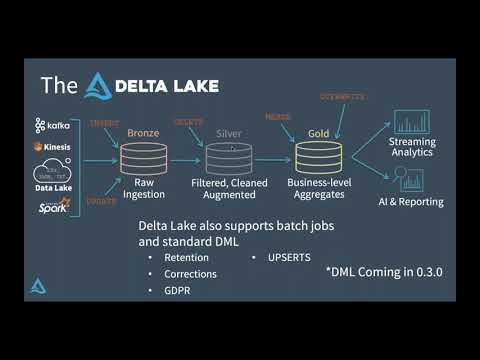
Optimizing spark jobs through a true understanding of spark core. Learn: What is a partition? What is the difference between read/shuffle/write partitions? How to increase parallelism and decrease output files? Where does shuffle data go between stages? What is the "right" size for your spark partitions and files? Why does a job slow down with only a few tasks left and never finish? Why doesn't adding nodes decrease my compute time? About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Read more here: Connect with us: Website: Facebook: Twitter: LinkedIn: Instagram: Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here.
- 202589Просмотров
- 6 лет назадОпубликованоDatabricks
Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks
Похожее видео









Популярное
Новини