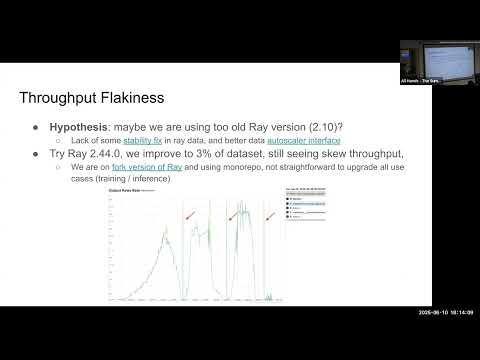
Struggling to scale your Large Language Model (LLM) batch inference? Learn how Ray Data and vLLM can unlock high throughput and cost-effective processing. This #InfoQ video dives deep into the challenges of LLM batch inference and presents a powerful solution using Ray Data and vLLM. Discover how to leverage heterogeneous computing, ensure reliability with fault tolerance, and optimize your pipeline for maximum efficiency. Explore real-world case studies and learn how to achieve significant cost reduction and performance gains. 🔗 Transcript available on InfoQ: 👍 Like and subscribe for more content on AI and LLM optimization! What are your biggest challenges with LLM batch inference? Comment below! 👇 #LLMs #BatchInference #RayData #vLLM #AI
- 2655Просмотров
- 9 месяцев назадОпубликованоInfoQ
Scaling LLM Batch Inference: Ray Data & vLLM for High Throughput
Похожее видео









Популярное
Новини