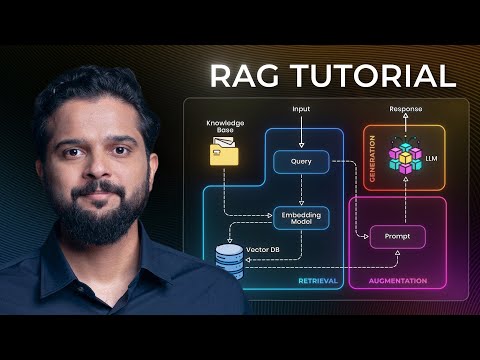
Multi-modal RAG with Docling: From PDF to Agentic AI Chatbot [hashtags] Unlock the power of multi-modal RAG in this complete walkthrough. We'll show you how to use Docling, a powerful open-source tool by IBM, to process complex PDF documents containing both text and images. Go beyond simple text extraction and learn to build a truly intelligent, agentic AI that understands the full context of your documents. Imagine an AI that doesn't just read text but also sees and understands the images in your files. This guide shows you how to build it from scratch, from processing documents to deploying a reasoning agent. ⭐️What You'll Learn: - How to implement a full Multi-modal Retrieval-Augmented Generation (RAG) pipeline. - Process PDFs with both text and images using Docling. - Automatically annotate images using the OpenAI API to create "enriched text" for your knowledge base. - Build a complete indexing pipeline, chunking documents and storing them in a Milvus vector database. - Construct an Agentic RAG system using LangGraph that can intelligently choose between multiple knowledge sources to answer questions. 🔑 Free Resources: ⛓️Connect with Us: 👍 Like | 🔗 Share | 📢 Subscribe | 💬 Comments + Questions LinkedIn: YouTube: @CaseDonebyAI Facebook: TikTok: @casedonebyai Github: SubStack: 🎬 Quick Navigation: 00:00 Introduction to Multi-modal RAG 00:43 What is Retrieval Augmented Generation (RAG)? 02:24 Introduction to Docling by IBM 03:49 Part 1: Basic PDF to Text Conversion with Docling 06:15 Enhancing Docling: Adding AI Image Descriptions with OpenAI 08:55 Saving Images as External References for Advanced RAG 11:01 Part 2: Building a Multi-Document Indexing Pipeline 11:16 Using Milvus as a Vector Database 15:09 Processing Multiple Folders into Separate Knowledge Bases 17:41 Part 3: Building an Agentic Multi-modal RAG System with LangGraph 20:07 LangGraph Agent Architecture Explained 21:14 Live Demo: Agentic Chatbot Choosing Between Knowledge Bases #genai #llm #agentic #aiagent #langgraph #docling #rag
- 10698Просмотров
- 4 месяца назадОпубликованоCase Done by AI
Multi-modal RAG with Docling: From PDF to Agentic AI Chatbot
Похожее видео









Популярное
Новини