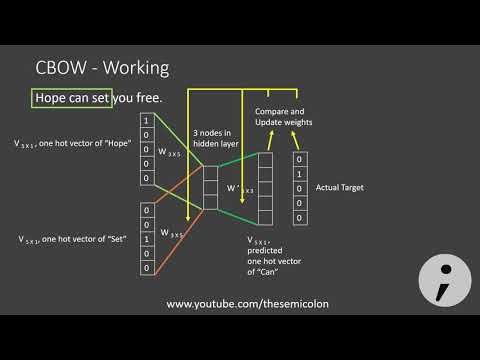
This video is part of Zero-to-Hero in NLP(Natural Language Processing),LLM(Large Language Model) and GenAI(GenerativeAI) Embeddings or embedding vector lie at the core of NLP and LLM, empowering machines to grasp the intricacies of human language. These vector representations enable machines to bridge the gap between raw text and meaningful understanding. As the field continues to evolve, the magic of embeddings will undoubtedly play a pivotal role in shaping the future of natural language processing. Have you ever wondered how these embedding vectors come into existence or are acquired? Or perhaps, considered the intricacies of pre-training embedding models on vast corpora? In this video, we will unravel the answers to these questions. To develop the intuition about how machine learns the context of human language, how embedding vectors are learned, Or how embedding vectors are generated, let us try to explore one of the technique which was a major breakthrough in field of embedding which is Word2Vec. Word2vec was created, patented, and published in 2013 by a team of researchers led by Mikolov at Google over these two papers: 🎯 Efficient Estimation of word representation in Vector Space and 🎯 Distributed Representations of Words and Phrases and their Compositionality Word2Vec is one of the most popular pretrained word embeddings developed by Google that transforms words into continuous vector representations It is trained on the Google News dataset (about 100 billion words) The core idea behind Word2Vec is to capture semantic relationships and similarities between words by representing them in a multi-dimensional space. It is A neural network-based method that learns word embeddings by predicting the likelihood of words in a context window. In this video we are going to learn the followings concepts: 🎯 Explore the significant breakthroughs in embedding technology throughout history. 🎯 Understanding Word2Vec 🎯 Understanding Continuous Bag of Words (CBOW) and Skip-Gram model 🎯 How training data is generated for Skip-gram model 🎯 Understanding how Skip-gram model is trained 🎯 Word2Vec Model projected on TensorFlow Embedding projector 🎯 How LLM is pre-trained to Predict Next word in the sequence Happy Learning, Pramod Singh PGD - Data Science Founder: About me :
- 365Просмотров
- 1 год назадОпубликованоDataScienceChampion
How Embedding Vector is generated | Pre-training Embedding Models | Learning Word2Vec and Skip-gram
Похожее видео











Популярное
Новини