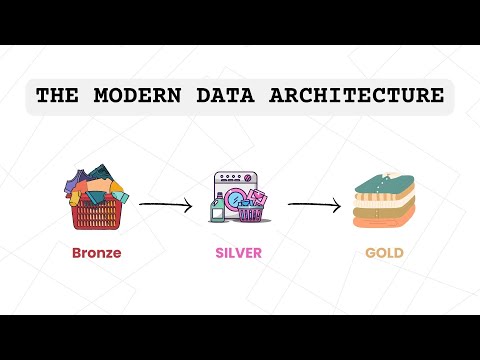
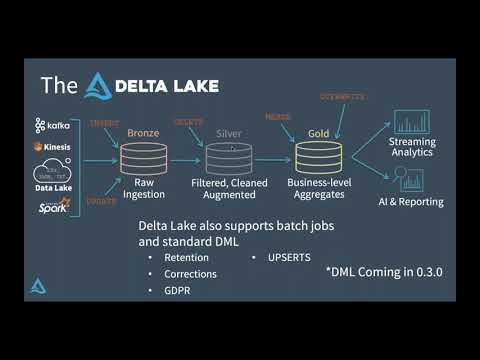
In this video, I walk you through a full-scale data pipeline for processing and analyzing news articles using the modern medallion architecture (Bronze → Silver → Gold). The pipeline is built on Databricks and utilizes PySpark, Delta Lake, and Hive Metastore, with integrated sentiment analysis using TextBlob and robust data quality validation mechanisms. 🔧 Technologies Used: Apache Spark (PySpark) Delta Lake (ACID Transactions) Azure Data Lake Gen2 (Storage) Hive Metastore / Unity Catalog (Metadata Management) TextBlob (NLP Sentiment Analysis) Databricks (ETL Orchestration) 📌 What You'll Learn: How to ingest data from APIs and store in Delta format Dynamic data quality checks and quarantining bad records Enriching data with NLP sentiment scores Building star-schema data models with fact/dim tables Writing clean data to Hive and exposing it for BI 📁 GitHub Repo: 👉 📌 Referenced Video - How to Provision the Medallion Architecture on Azure ADLS using Terraform: - Medallion Architecture Explained: From Raw Data to Business Insights: - How to Create Azure Key Vault and Connect with Databricks: - How to Design a Data Model Using Python and SQLite: - How to Connect to Databricks from PowerBI: ----- 🔥 Don't forget to Like, Comment, and Subscribe for more data engineering content!#dataengineering #Databricks #DeltaLake #ApacheSpark #PySpark #NLP #SentimentAnalysis #BigData #ETL #Hive #Lakehouse #MedallionArchitecture
- 3950Просмотров
- 7 месяцев назадОпубликованоThe Data Signal
📰 End-to-End News Data Pipeline | Databricks, PySpark, Delta Lake, Hive, and Sentiment Analysis
Похожее видео








Популярное
Новини