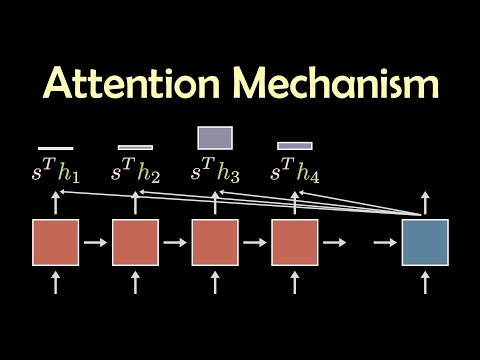
Attention is one of the most important concepts behind Transformers and Large Language Models, like ChatGPT. However, it's not that complicated. In this StatQuest, we add Attention to a basic Sequence-to-Sequence (Seq2Seq or Encoder-Decoder) model and walk through how it works and is calculated, one step at a time. BAM!!! NOTE: This StatQuest is based on two manuscripts. 1) The manuscript that originally introduced Attention to Encoder-Decoder Models: Neural Machine Translation by Jointly Learning to Align and Translate: and 2) The manuscript that first used the Dot-Product similarity for Attention in a similar context: Effective Approaches to Attention-based Neural Machine Translation NOTE: This StatQuest assumes that you are already familiar with basic Encoder-Decoder neural networks. If not, check out the 'Quest: For a complete index of all the StatQuest videos, check out: If you'd like to support StatQuest, please consider... Patreon: ...or... YouTube Membership: ...buying one of my books, a study guide, a t-shirt or hoodie, or a song from the StatQuest store... ...or just donating to StatQuest! Lastly, if you want to keep up with me as I research and create new StatQuests, follow me on twitter: 0:00 Awesome song and introduction 3:14 The Main Idea of Attention 5:34 A worked out example of Attention 10:18 The Dot Product Similarity 11:52 Using similarity scores to calculate Attention values 13:27 Using Attention values to predict an output word 14:22 Summary of Attention #StatQuest #neuralnetwork #attention
- 405563Просмотров
- 2 года назадОпубликованоStatQuest with Josh Starmer
Attention for Neural Networks, Clearly Explained!!!
Похожее видео










Популярное
Новини