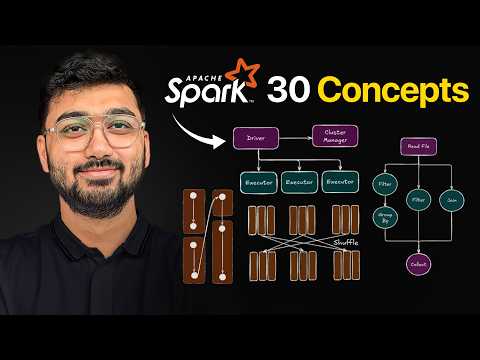
Welcome to this ~6 hour Masterclass on Delta Lake. We'll be covering deep-dive concepts with extensive hands-on labs on Azure Databricks using PySpark. This video will set a very strong base / foundation for Lakehouse concepts or if you're preparing for Data Engineering roles In this video, you will master: - The Fundamentals: Problems with Data Lake and how Delta Lake solves those problems? - Core Internals: A deep dive into the _delta_log to understand how the magic happens, Optimistic Concurrency Control, Pessimistic Concurrency Control - Key Features: Time Travel, Schema Evolution, and Schema Enforcement / Validation, Shallow Cloning, Deep Cloning, Deletion Vectors, Managed & External Tables - Performance Tuning: Solving the "Small File Problem" - Advanced Optimization: OPTIMIZE, VACUUM, ZORDER, Liquid Clustering Codes (Delta Lake Masterclass): Chapters 00:00:00 Introduction & Course Outline 00:02:28 Challenges with Data Lakes 00:04:07 Lack of ACID Support (ACID Explained) 00:04:59 Atomicity 00:08:10 Consistency 00:13:27 Isolation 00:15:28 Durability 00:20:15 Lack of UPDATE, MERGE, DELETE Operations 00:21:59 Data Reliability & Quality Issues 00:24:12 Lab Architecture on Azure 00:27:49 Lab Setup on Azure 00:35:57 DML Operations on Delta Tables (Lab) 00:44:31 Uncovering the Delta Log (_delta_log) 01:06:07 How Delta Lake Computes the Latest State 01:13:47 How Delta Lake's Transaction Log Scales 01:21:48 Pessimistic Concurrency Control 01:27:57 Optimistic Concurrency Control 01:35:32 Time Travel & Versioning 01:48:26 Schema Validation 02:16:40 Schema Evolution 02:47:54 Converting Parquet to Delta 02:52:13 Managed & External Tables 02:58:46 Deletion Vectors (Copy on Write vs. Merge on Read) 03:22:15 Cloning Delta Tables 03:22:37 Shallow Clone Explained 03:25:53 Deep Clone Explained 03:28:09 Shallow Clone Lab 03:48:25 Deep Clone Lab 03:54:28 CTAS (CREATE TABLE AS SELECT) vs. Deep Clone 03:57:43 The Small File Problem 04:01:20 Optimization Techniques 04:01:27 OPTIMIZE Command & Bin Packing Algorithm 04:07:47 OPTIMIZE Lab 04:21:34 Root Causes of the Small File Problem 04:26:03 Manual OPTIMIZE 04:26:40 Optimize Write Explained 04:29:30 Optimize Write Lab 04:33:40 Auto Compaction 04:39:06 VACUUM Command 04:43:05 VACUUM Lab 04:52:17 ZOrdering 05:06:47 ZOrdering Lab 05:20:17 Liquid Clustering 05:33:46 Liquid Clustering Lab 05:40:06 How to Choose Liquid Clustering Columns 05:44:26 Conclusion My Social Media Handles: LinkedIn: YouTube Channel: @afaqueahmad7117 Playlists: Interview Preparation: Spark Performance Tuning: Data Engineering Roadmap: How I Mastered Data Modeling: Cracking Interviews @ Apple, Uber, Atlassian, Databricks: Github: Spark Performance Tuning Codes: #databricks #databrickstutorial #deltalake #dataengineering #bigdata
- 31972Просмотров
- 3 месяца назадОпубликованоAfaque Ahmad
Delta Lake Masterclass | Azure Databricks | PySpark | From Zero To Hero
Похожее видео










Популярное
Новини