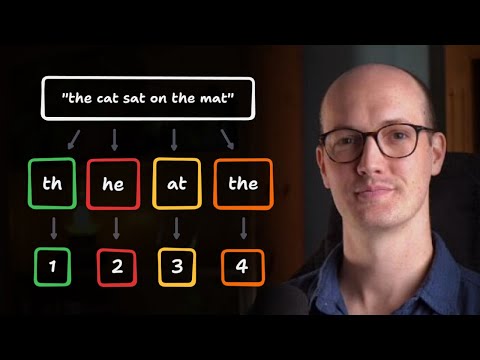
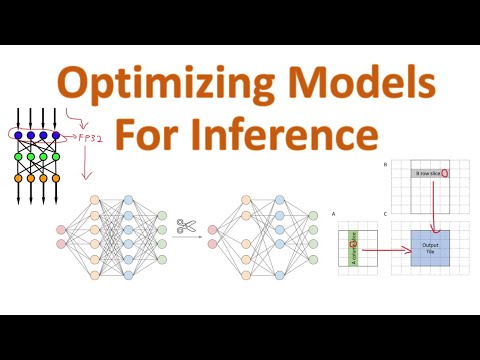
Video 1 of 6 | Mastering LLM Techniques: Inference Optimization. In this episode we break down the two fundamental phases of LLM inference. Prefill ( . context or prompt loading) – the compute-intensive step that ingests the entire prompt and builds the KV cache. Decode – the token-by-token generation phase that is typically memory-bandwidth-bound and far more latency-sensitive. 📚 Source & Credits NVIDIA’s excellent post “Mastering LLM Techniques: Inference Optimization” on the NVIDIA Developer Blog: Special thanks to Kyle Kranen for recommending the post:
- 7041Просмотров
- 6 месяцев назадОпубликованоFaradawn Yang
AI Optimization Lecture 01 - Prefill vs Decode - Mastering LLM Techniques from NVIDIA
Похожее видео









Популярное
Новини