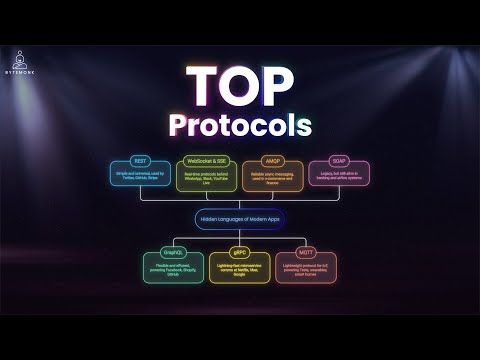
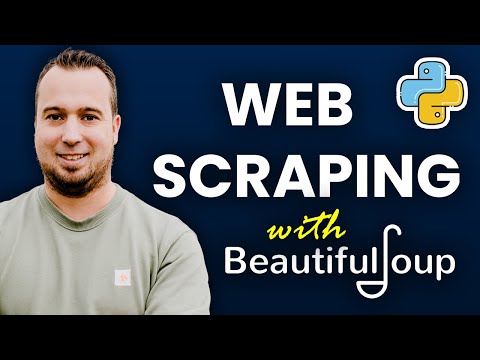
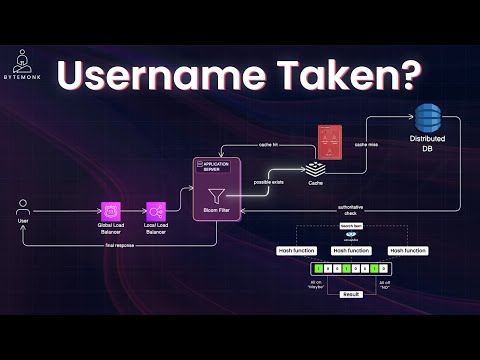
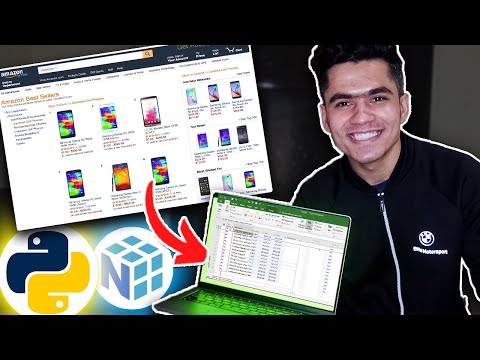
Get a free trial on any proxy product with my link: Thanks to team Decodo team for providing me free credits and sponsoring this video! Have fun! Scraping e-commerce data at scale is tough. CAPTCHAs, IP bans, rate limits, and JavaScript-rendered content can kill your scripts. In this video, I walk through how I built a scalable scraping pipeline—from a basic Python script to a production-ready system—using **Decodo's residential proxies and Site Unblocker API**. 📌 You’ll learn: - How to scrape sites like and - How to helps bypass bot protection using proxy rotation - How to scale scraping with proxies, retries, and session rotation - What a real-world price-tracking architecture looks like on AWS/GCP Whether you're tracking competitor prices or building a research tool, this breakdown covers it all—from code to cloud deployment. 👍 Like, 🔔 Subscribe, and explore more tech explained simply! Timestamps: 0:00 – Why Web Scraping Isn’t Easy at Scale 0:40 – Web Scraping Basics with Python & BeautifulSoup 1:41 – Intro to Proxy Rotation & Rate Limits 2:18 – Using Free Proxies with Retry Logic 4:04 – Decodo Setup: Residential Proxies & Sticky Sessions 5:15 – Python Script with Decodo to Scrape BooksToScrape 6:38 – Scraping Amazon with Decodo’s Site Unblocker 7:10 – Real-World Price Tracker System Architecture (Cloud) 8:18 – Monitoring, Alerts & Data Pipelines 11:10 – What’s Next: All-in-One Scraping API AWS Certification: AWS Certified Cloud Practioner: AWS Certified Solution Architect Associate: AWS Certified Solution Architect Professional: #WebScraping #proxyserver #PythonScraper #ProxyRotation #AmazonScraping #SystemDesign #Bytemonk
- 24998Просмотров
- 5 месяцев назадОпубликованоByteMonk
How I Scraped Amazon Without Getting Blocked | Python Proxy
Похожее видео








Популярное
Новини